V8 es el nombre que se le da al engine (motor) que utiliza Chrome para compilar Javascript.
Si ya sabes aunque sea un poco de como interactua Javascript con un navegador esto no te causará ninguna confusión. Pero antes de entender como funciona V8 es vital entender lo básico de los engines y de la compilación de lenguajes.
Para eso te recomiendo:
¿Listo? Si ya sientes que tienes todas las bases. Podemos continuar.
Como te podrás imaginar no solo hay un engine. Hay bastantes que fueron creados para distintos runtime environments (ambientes de ejecución).
*Un runtime environment no es nada mas que el encargado de compilar y ejecutar código Javascript. En la web son todos los navegadores, pero existen otros para diferentes propósitos. Por ejemplo Deno y NodeJS son para correr Javascript en los servidores.
| Engine | Runtime Environments |
| V8 | Chrome, Edge, Opera, NodeJS, Deno |
| SpiderMonkey | Firefox, |
| JavaScriptCore | Safari |
| EdgeHTML | Previously used by Edge |
¿Qué es lo que hace a V8 diferente de los demás? En esencia nada. Pero lo que ha hecho que gane tanta tracción y se haya vuelto tan sonado es su rendimiento.
¿Cómo es que logra un rendimiento por encima de los demás?
Bueno hay varias razones. Veámoslo con un ejemplo simple:
function helloWorld() {
console.log("Hello World!")
}¿Qué es lo que pasa detrás de cámaras para que la computadora pueda interpretar que hacer con este texto?
Las fases de procesamiento
Fase de Parseo
En esta fase se parsea el texto escrito para poder transformarlo a lenguaje máquina.
Parsear no es otra cosa que analizar un texto para identificar su estructura sintáctica y extraer la información relevante.
Durante el parseo se realizan 2 cosas de importancia:
Análisis Léxico (Tokenización)
Primero que nada el compilador desglosa el código escrito en partes más pequeñas llamadas tokens.
Un token es cualquier parte del código que se necesita para interpretarlo correctamente. Esto quiere decir palabras reservadas, símbolos de puntuación, identificadores para los valores de referencia, etc.
Por lo tanto, los tokens serían algo así:




Esos 4 no son todos por supuesto. A continuación puedes ver la lista completa de los tokens del código anterior:
[
{ type: 'keyword', value: 'function' },
{ type: 'identifier', value: 'helloWorld' },
{ type: 'punctuation', value: '(' },
{ type: 'punctuation', value: ')' },
{ type: 'punctuation', value: '{' },
{ type: 'identifier', value: 'console' },
{ type: 'punctuation', value: '.' },
{ type: 'identifier', value: 'log' },
{ type: 'punctuation', value: '(' },
{ type: 'string', value: 'Hello World!' },
{ type: 'punctuation', value: ')' },
{ type: 'punctuation', value: '}' }
]La parte de los tokens es importante porque ayuda a validar que precisamente todo lo que está escrito en el código pueda ser mapeado a un token válido. Errores de puntuación o typos causarían que la compilación se detuviera en esta etapa.
Generación del AST y Análisis Sintáctico
Una vez generados los tokens estos se utilizan para generar el Abstract Syntax Tree o AST (árbol de sintaxis abstracta) del código.
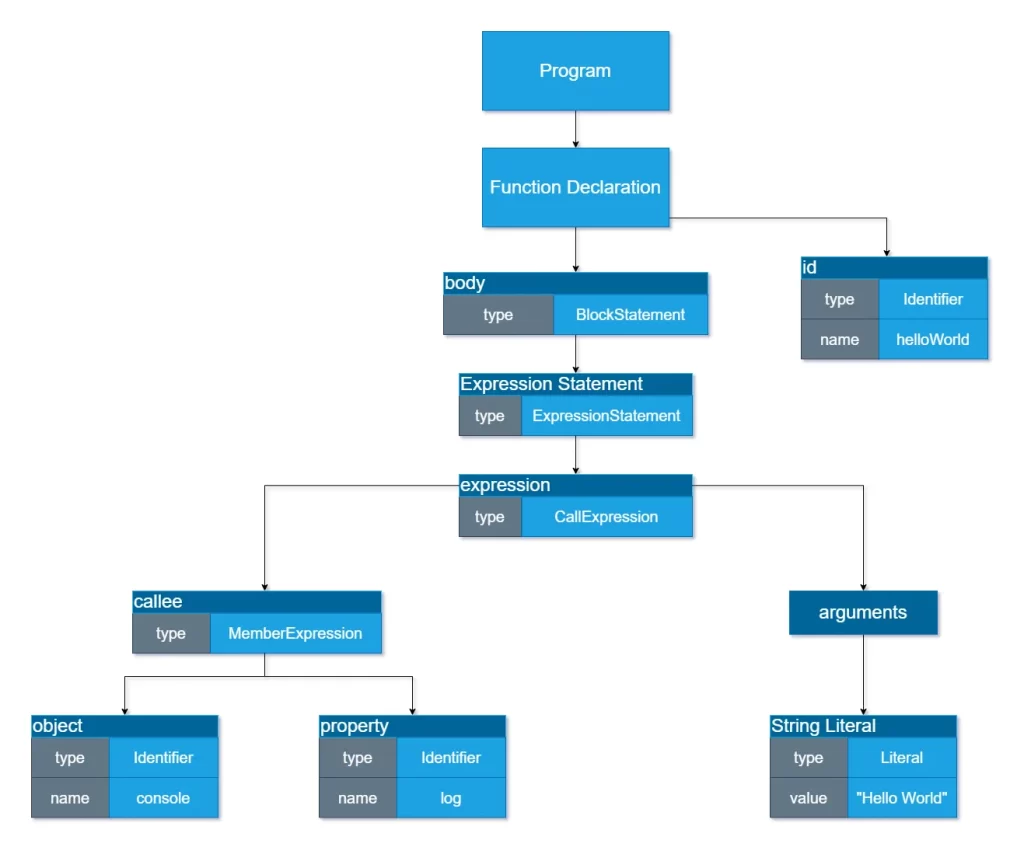
Cada nodo del árbol representa una sección del código. Y es importante porque esto ayuda a que la máquina entienda como intepretar el orden del mismo.
*Si deseas ver un ejemplo más complejo de un AST te recomiendo leer: Qué es un AST – Abstract Syntax Tree.
La generación del AST permite realizar en el análisis sintáctico. Esto permite encontrar otro tipo de errores. Por ejemplo, puede ser que los tokens generados sean válidos, pero tal vez no apuntan a lugares válidos de memoria o no son aceptados dentro de una cierta expresión.
Fase de Compilación
En esencia hay 2 formas de compilar el código: con un intérprete o con un compilador.
V8 no usa ninguna de las 2 y en su lugar utiliza una compilación Just in Time (JIT), lo cual mejora el rendimiento.
Esto lo logra utilizando 2 herramientas: Ignition y TurboFan.
Ignition – Intérprete
El intérprete por defecto de V8 se llama Ignition. Este hace los pasos que realizaría un interpretador normal. Solo que a medida que ejecuta el código desde el AST va generando bytecode.
El bytecode es un código intermedio entre JS y el lenguaje máquina que es más eficiente de ejecutar que el código original de JS.
Turbo Fan – Compilador Just-in-Time
A medida que Ignition ejecuta el bytecode se recopilan estadísticas sobre el rendimiento del código y se identifican las partes del mismo que se ejecutan con mayor frecuencia. A estas partes se les denomina como las partes “hot”.
Las partes “hot” son compiladas en código máquina nativo altamente optimizado por TurboFan.
El compilar solo algunas partes del código en lugar de todo acelera el proceso de ejecución. Aún mejor, como se le da prioridad a las secciones más usadas se ayuda a optimizar las partes más importantes del código.
Fase de Ejecución
Se ejecuta el código utilizando la Memory Heap (Memoria de Almacenamiento Libre) y la Call Stack (Pila de Llamadas).
Técnicamente en nuestro código no estamos ejecutando nada. Se crea la función en memoria pero nunca se manda a llamar…así que hagamos de cuenta que sí la llamamos.
helloWorld();Como nuestro código es muy simple la representación de la Call Stack y la Memory Heap también lo son:
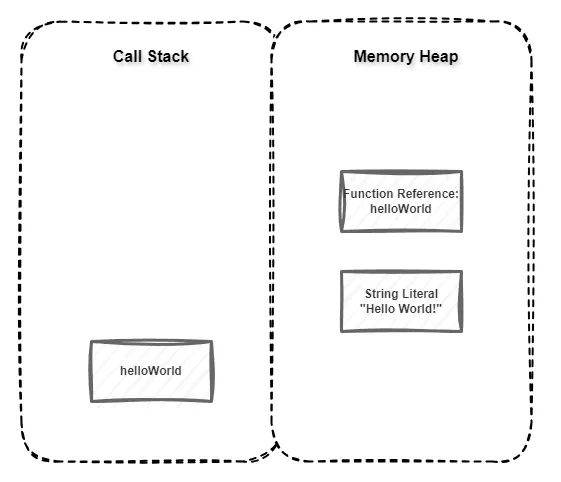
Nuestra Memory Heap del lado derecho tiene solo 2 objetos en memoria:
- La referencia en memoria de nuestra función. Identificada con el nombre que le dimos:
helloWorld - El valor en memoria de la cadena de texto que estamos usando: “Hello World!”
Por otro lado en la Call Stack se agrega un execution context (contexto de ejecución) para la función helloWorld en el momento que se llama a la misma. La función permanecerá ahí hasta que se termine su ejecución. Una vez esto ocurra se quitará de La Call Stack.
*En este caso ese momento dura un instante, ya que nuestra función es muy simple y acaba tan pronto como inicia.
Por supuesto si tenemos más funciones llamándose, la Call Stack irá apilando y quitando los execution contexts conforme se llamen y terminen.
*¿Gustas ver más a fondo qué es eso de los execution context? Te recomiendo leer del Global Execution Context y del Function Execution Context.